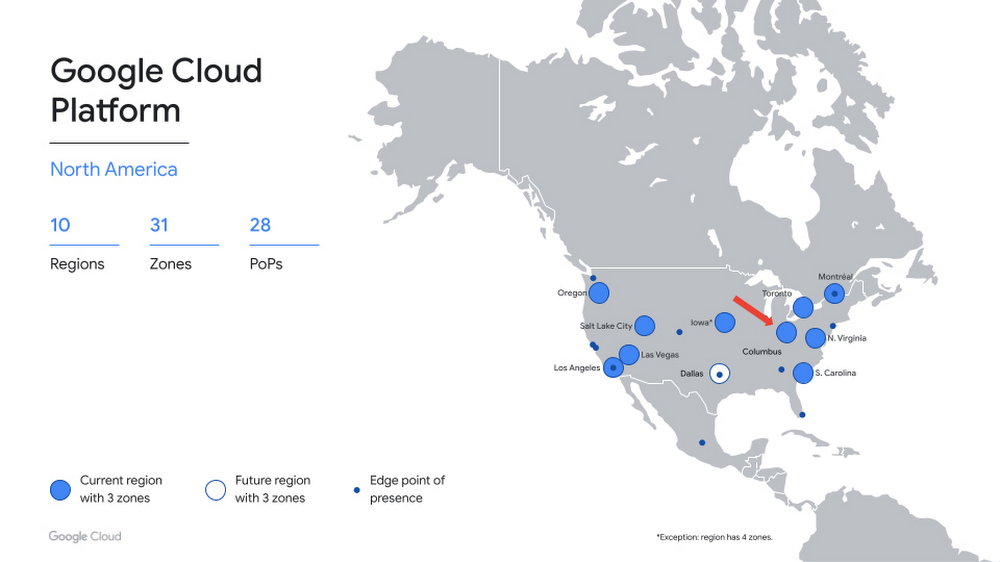
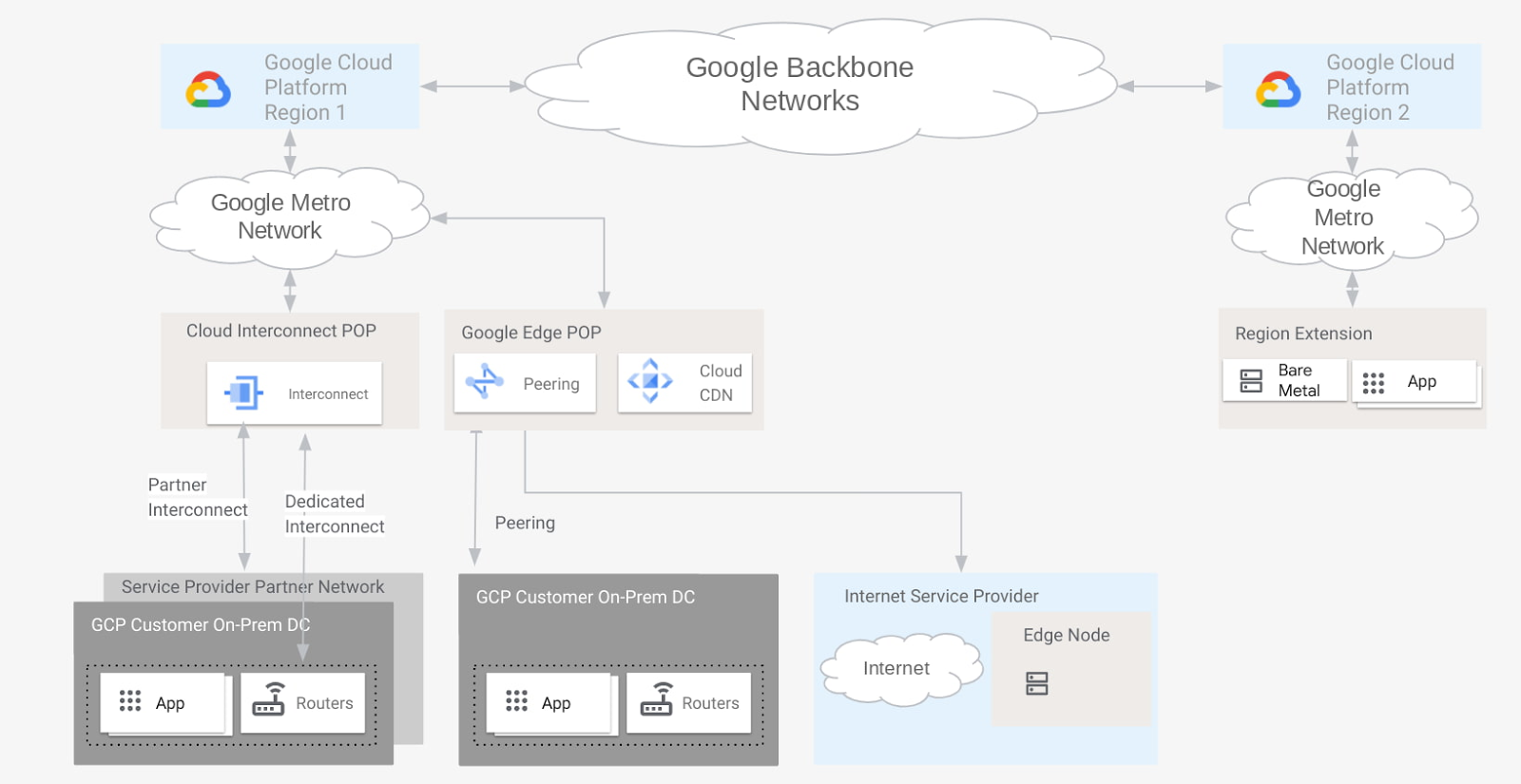
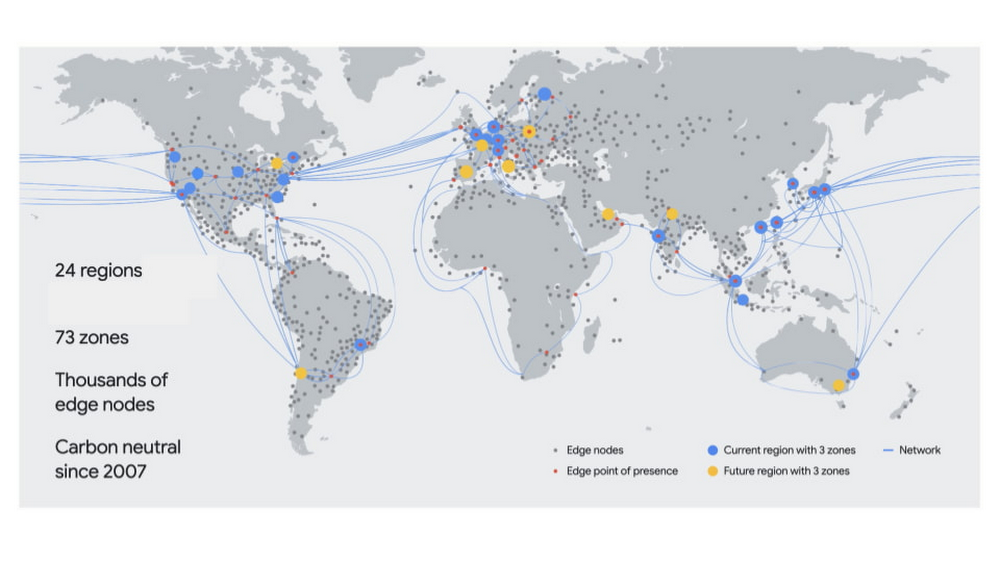
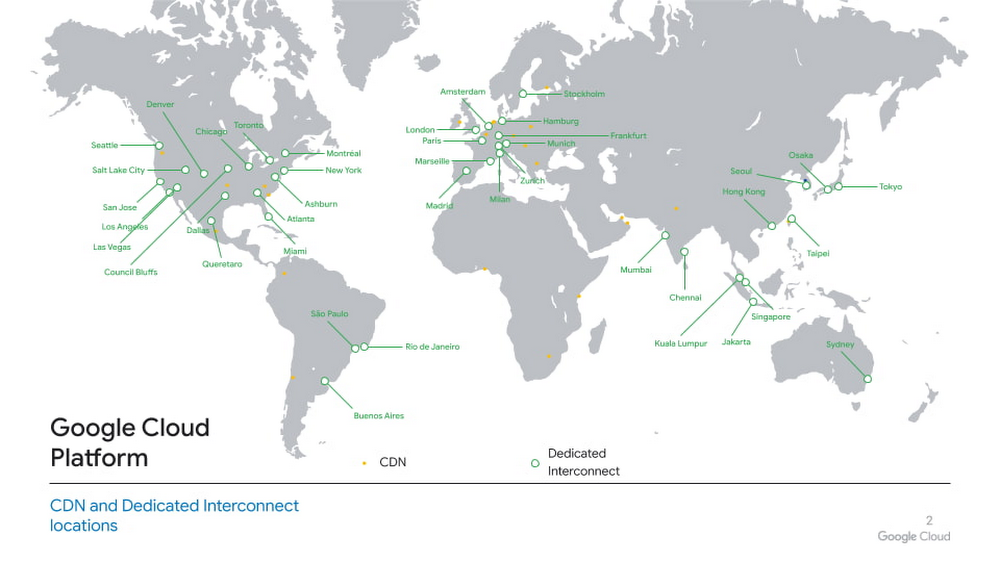
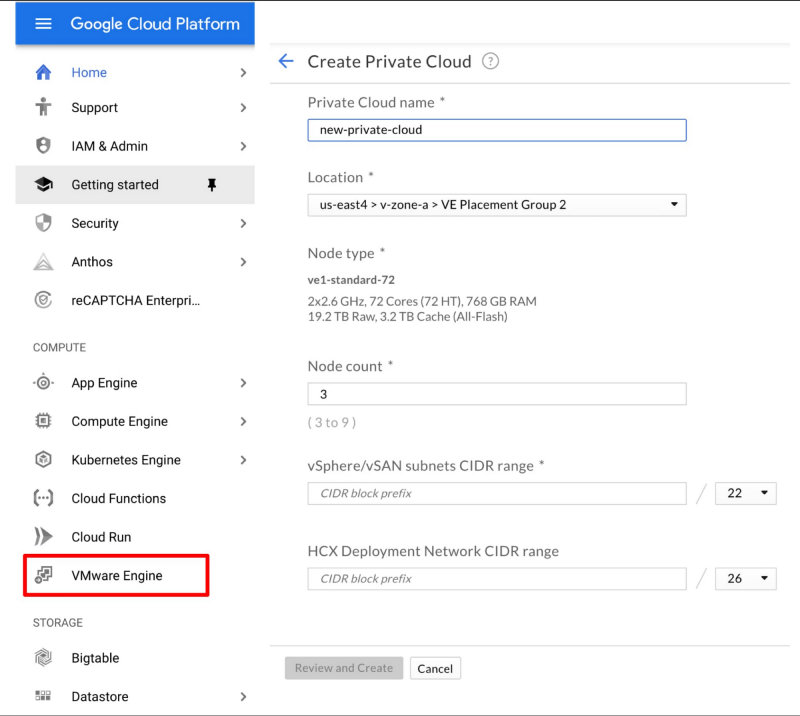
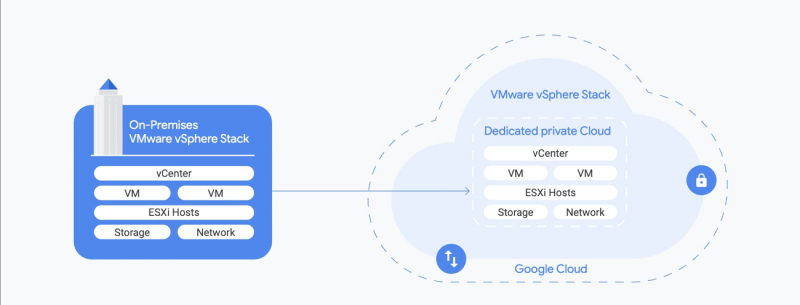
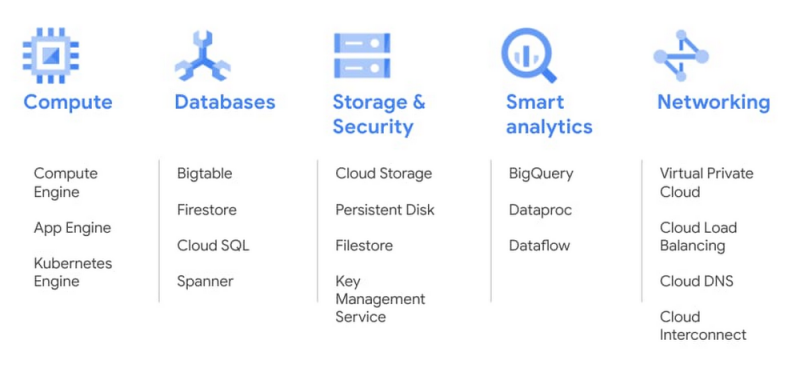
COMPUTE
Compute Engine — изменить название памяти, оптимизированные виртуальные машины: GA
COMPUTE
Compute Engine — изменить название памяти, оптимизированные виртуальные машины: GA
Для того, чтобы более четко определить экземпляры VM в качестве членов машины типа семейства памяти оптимизированных все n1-ultramem и n1-megamem виртуальных машины имели их префикс «n1» изменен на «m1».
Документация
Compute Engine — постоянные дисковые запланированные моментальные снимки: GA
Используйте SNAPSHOT расписание регулярно и автоматически создавать резервные копии ваших рабочих нагрузок Compute Engine, а также ваши зональные и региональные упорные дисков. И определить, как долго держать снимки с политикой хранения снимков.
Документация
Compute Engine — пользовательский контроллер интерфейса виртуальной сети: бета
Включите более высокую пропускную способность сети с более эффективной сетью доставки для отправки трафика и от ваших экземпляров виртуальных машин. Специально разработанный для Compute Engine, то gVNIC устройство и драйвер будет работать на всех Google Cloud виртуальных машин, кроме памяти оптимизированных типов машин.
Документация
Kubernetes двигателя — контейнер родной балансировки нагрузки: GA
Повышение видимости трафика, производительность и масштабируемость за счет создания услуг с использованием сети оконечных групп (NEGS). NEGS обеспечить запросы к вашим услугам распределены непосредственно в контейнеры, обслуживающих запросы.
Документация | Блог
Kubernetes двигатель — дозирующее использование: GA
Просмотр профилей использования кластеров Kubernetes двигателя и связать использование отдельных команд, бизнес-единица, приложения или среды в вашей организации на основе имен и ярлыков. дозирующее Использование облегчает принятие Kubernetes в среде многопользовательской.
Документация
Kubernetes двигателя — containerd: GA
Использование containerd вместо Докер в качестве контейнера для выполнения Kubernetes на контейнерном оптимизированным OS и Ubuntu для выполнения приложений внутри контейнеров и ручка взаимодействия с базовой операционной системой.
Документация
Kubernetes двигатель — окна обслуживания: бета
Поддерживайте больший контроль над вашими кластерами Kubernetes Engine с возможностью настройки времени автоматического обслуживания кластера, например, когда авто-обновление может и не может произойти.
Документация
Kubernetes двигатель — доступ частный мастер кластера из локальных: беты
Поддерживать строгую безопасность и соблюдение, позволяя родную связь между сетью локальных и Google принадлежащей сетью VPC, что Саваофа мастером-кластером.
Документация
Облако Run — метки: бета
Установить, изменять и удалять ярлыки на вашей службы и пересмотров Cloud Run. Используйте метки для фильтра счетов, журналов, метрики и других данных для идентификации ресурсов, используемых отдельными владельцы, командами или центры затрат для распределения затрат и выставления счетов срывов.
Документация
Облако Run — расширение отчетов об ошибках и масштабирования метрик: бета
Используйте Stackdriver, чтобы отслеживать, сколько экземпляров активно служу трафик для службы с новой схемой «Billable контейнера времени экземпляра», и просматривать лучшие ошибки приложения в этой службе с таблицей «Error Reporting».
Документация
Облако Run — одинарный поддержка КПГР: бета
Развертывание КПГР услуги Cloud Run — теперь с поддержкой одинарных КПГР вызовов. КПГР является высокопроизводительным, с открытым исходным кодом рамки универсальной RPC.
Документация
Compute Engine — N2 типа общего назначения машины: GA
Создать широкий спектр предустановленных или пользовательских экземпляров VM с нашими новыми типами N2 машин. На основе процессоров второго поколения Intel Xeon масштабируемой, типы машин N2 предлагают до 80 виртуальных ЦП и в общей сложности 640 Гб памяти, на базовой частоте 2,8 ГГц, и пролонгированное все-жильный турбо до 3,4 ГГц.
Документация
Compute Engine — зональные оговорки: GA
Убедитесь, что ваш проект имеет ресурсы для будущего спроса, в том числе дорожных шипов, большие миграции, резервного копирования и аварийного восстановления, а также запланированного роста. Резервные ресурсы, включая местные, виртуальные ЦП твердотельных накопителей, а также графические процессоры в определенной зоне — и добавить совершенное использование скидки для большей экономии.
Документация
Compute Engine — повышенная производительность системы хранения данных блока: GA
SSD упорные диски теперь предлагают удвоить пропускную способность от записи для экземпляров VM с 16 или более ядер и 100K IOPS чтения для экземпляров VM с 64 или более ядер.
Документация
Compute Engine — увеличение общей емкости для постоянных дисков: GA
Приложить до 257 ТБ постоянной памяти на диске для каждого экземпляра VM — значительный прирост по сравнению с предыдущим лимитом 64 ТБ.
Документация
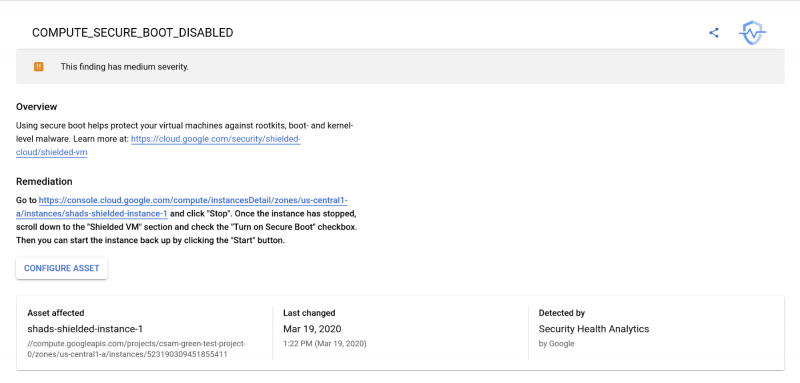
Compute Engine — OS Войти Политика и ведение журнала аудита: GA
Управление доступом к экземплярам с политикой организации и ведения журнала аудита для обеспечения того, чтобы все новые проекты, а также экземпляры виртуальных машин, созданных в них, имеют OS Логин включен. Отслеживание событий и мероприятий, как добавление, удаление или обновление ключа SSH, или удаление информации POSIX.
Документация
Google Kubernetes Engine — Rapid, Regular, и стабильные каналы выпуска: бета
Создание новых кластеров с помощью Rapid, Regular, или стабильный канал выхода. Каналы представляют уровень стабильности и свежесть версий GKE, и вы можете выбрать канал наиболее выровненный с профилем риска и потребностями бизнеса.
Документация
GKE — вертикальный стручок автомасштабирование: GA
Получить более стабильной, эффективной стручки автоматически. Если эта функция включена, вертикальная черта стручок автомасштабирования рекомендует, и может автоматически обновлять, память и процессор запросы и ограничение для контейнеров в ваших стручках на основе наблюдаемого использования.
Документация
GKE — узел автоматической инициализации: GA
Создать новый пул узла в кластере GKE autoscaler, если ни один из существующих пулов узлов не может вместить в ожидании стручков или при работе стручков на новом пуле узлов значительно дешевле.
Документация
App Engine — Java 11 на стандартной среде App Engine: GA
Создание и развертывание приложения с Java 11, который работает надежно под нагрузкой тяжелой и с большими объемами данных. Запустите приложение в своей собственной безопасной, надежной среде, независимо от аппаратного обеспечения, операционной системы, или физического местоположения сервера.
Документация
Google Kubernetes Engine — Пакетное на GKE: бета
Запустите пакетные нагрузки в облаке с использованием Kubernetes с гибкими средствами, которые динамически размещаемыми в соответствии с вашими потребностями и бюджет. Создание очередей, расставить приоритеты заданий и зависимости ручки с функциями и фамильярности традиционного пакетного задания планировщика.
Документация
Compute Engine — расширение EGRESS ограничения на малых случаях VM: GA
Наслаждайтесь повышенной пропускной способностью для ваших маленьких экземпляров VM автоматически. Мы увеличили максимальную скорость исходящего трафика для всех новых и существующих виртуальных машин с двумя и четырех до 10 виртуальных ЦП Gbps — без дополнительных действий, требуемых от вас.
Документация
Compute Engine — 100 Gbps виртуальные машины: бета
Достижение 50-100 Гбит пропускной способности сети VM для экземпляров V100 и Т4 ГПУ VM с помощью виртуальной сетевой интерфейс Compute Engine (gVNIC).
Документация
Compute Engine — operations.wait: GA
Снизить частоту опроса состояния операции и помогают более эффективно использовать ваши запросы-за-вторых квот. Глобальные, региональные и зональные operations.wait методы ждать указанной операции ресурс для возврата, как это сделано, или для запроса, чтобы поразить двухминутный срок, а затем получить его.
Документация
Compute Engine — отключить или ограничить автомасштабирование в управляемых группах экземпляра: GA
Возьмите под свой контроль над размером ваших зональных или региональных управляемых групп например, путем временного отключения или ограничений направления автомасштабирования только масштабы, все, сохраняя при этом своей конфигурации, так что он может быть включен снова.
Документация
Compute Engine — единственный арендатор VM аренда миграция: GA
Перемещение между многопользовательским и единственным арендатором узлами, или между узловыми группами единственным арендатора корректировать договор аренды на основании требований рабочей нагрузки.
Документация
Compute Engine — принести вам собственную лицензию (бель) V2: бета
Запустите рабочую нагрузку для Windows — и использовать существующие лицензии ОС Windows — на Compute Engine. Новые функции включают в себя объединение ресурсов единственного нанимателем узлов и способность к экземплярам бели жить Migrate для событий технического обслуживания для других узлов в бассейне без каких-либо простоев.
Документация
Compute Engine — единоличный-арендатор autoscaler: бета
Автоматически управлять размером ваших групп узлов единственным арендатора. Настройка группы узлов autoscaler для создания дополнительных экземпляров виртуальных машин, когда есть недостаточная пропускная способность и удаление пустых узлы, чтобы уменьшить затраты.
Документация
Compute Engine — сохраняющие состояние управляемых групп экземпляров: бета
Построить высокодоступные развертываний с состоянием рабочих нагрузок, таких как базы данных, по обработке данных приложений, унаследованных монолитные приложения, и долго выполняющиеся пакетные вычисления с контрольной точки. Улучшение работоспособности и устойчивости при сохранении уникального состояния каждого экземпляра.
Документация
Compute Engine — управляемый экземпляр группа свитки проверка: GA
Проверить, является ли обновление свитка была завершена с gcloud инструментом командной строки или API. Или использовать Cloud Console интерфейс Google, чтобы увидеть текущее и планируемое количество экземпляров обновляются.
Документация
Compute Engine — настроить региональный управляемый экземпляр группы перебалансирование: GA
Контроль следует ли сохранить или отключить поведение перераспределения региональных групп управляемых экземпляров — балансирует ли региональная управляемый экземпляр группа экземпляры активно, как это делает сейчас по умолчанию, или оппортунистический, при изменении размера группы.
Документация
DATA АНАЛИТИКА
Облако Dataproc — поддержка GPU: GA
Повышение производительности рабочих нагрузок, в том числе машинного обучения и обработки данных, путем присоединения графических процессоров (GPU) для ведущего и рабочих узлов Compute Engine в кластере Облако Dataproc. Выберите один из вариантов, включая NVIDIA Tesla P100, V100, и Р4 графических процессоров.
Документация
BigQuery ML — K-средства кластеризации поддержки: GA
Используйте неконтролируемое обучение для агрегирования данных в кластеры и идентифицировать естественные группировки. К-средства алгоритм используется для всего, от понимания сегментации клиентов в области компьютерного зрения и астрономии.
Документация
Облако Dataprep по Trifacta — API и улучшенной функции: GA
Управление и мониторинг заданий подготовки данных программно поставить воспроизводимые результаты данных с API Cloud Dataprep. И подготовка делают данные более интуитивной с новыми функциями, включая макросы, преобразование примера, и кластер чистые.
Документация
Облако Dataflow — Python потоковый режим: GA
Исследуйте новейшее Облако DataFlow потокового вариант для трубопровода Python, включая AutoScale, процедить, обновление Streaming Engine и обновление счетчика.
Документация
поддержка Python 3 — Cloud Dataflow: GA
Автор ваших трубопроводов Apache Beam в Python 3 и запустить на облаке DataFlow. Apache Beam прекратит поддержку Python 2 в новых версиях, начиная с 1 января 2020. Мы рекомендуем пользователям Облако DataFlow перенести свои трубопроводы на Python 3.
Документация
BigQuery — аудит журналы v2: GA
Получить более полное представление о ваших ресурсах BigQuery с BigQueryAuditMetadata, более новым форматом журнал аудита сообщений. Понимание взаимодействия ресурсов и определить, какие таблицы были прочитаны и записаны с помощью данного задания запроса и таблицы, которые истекли.
Документация
BigQuery и BigQuery ML — новый регион: GA
BigQuery и Biguery ML теперь доступны в Южной Каролине (США) Восток1 региона.
Примечания к выпуску
Облако Dataflow — Гибкое ресурсов Планирование: GA
Сокращение затрат пакетной обработки — без изменения коды трубопровода. FlexRS использует передовые методы планирования, DataFlow Перемешать и сочетание Preemptible экземпляров виртуальных машин и регулярных виртуальных машины, чтобы сократить расходы рабочих до 40%.
Документация
BigQuery Transfer Data Service — учетная запись службы поддержки: бета
Настройка запланированного запроса для проверки подлинности с помощью аккаунта Google, связанного с проектом Google Cloud Platform. Затем учетная запись может выполнять задания, связанные со своими учетными данными службы, а не учетные данные конечного пользователя, таких как запланированная запроса.
Документация
BigQuery — целое число, на основе диапазона разделение: бета
Создание и использование таблиц секционированных целого числа столбец в BigQuery. Просто указать диапазон целого числа на основе и таблица будет разделена в соответствии с целочисленных значений в этом столбце.
Документация
Облако данных Fusion: GA
Оцифровка, чистят, преобразования и интеграции данных из SAP HANA, Teradata, MongoDB, Salesforce, и многое другое. Выберите из широкой библиотеки предварительно настроенных коннекторов и преобразований, используя визуальный интерфейс точки и нажмите для кода свободного развития ETL и ELT трубопроводов.
Документация
Cloud Storage — BigQuery Передача данных Услуга: GA
Расписание повторяющихся нагрузок данных от Cloud Storage в BigQuery. Теперь вы можете загрузить данные по установленному графику — и загружать только новые данные в таблицу назначения.
Документация
Облако Dataproc — SparkR типы заданий: GA
Использование dplyr подобные операциям на наборах данных практически любого размера, хранящихся в Cloud Storage с помощью SparkR, пакет, который обеспечивает легкий конец переднего использовать Apache искру от R. SparkR также поддерживает распределенные машинное обучение с использованием MLlib.
Документация
BigQuery ML — предварительная обработка данных: GA
Streamline и упростить вашу модель машинного обучения строит — и поддерживать преобразования в соответствии между обучением и умозаключениями. Preprocess и преобразование данных с помощью простых функций SQL и автоматически применить эти преобразования на этапе прогнозирования.
Блог |
Документация |
Руководство
Потоковый — наблюдаемость: GA
Просмотр трубопровода, а также любую другую работу, с интерфейсом мониторинга Dataflow веб-основе. См и взаимодействовать со списком заданий DataFlow. Проверка состояния, выполнения и SDK версии задания, выполните. И найти ссылки на информацию об услугах, работающих под управлением вашим трубопровод.
Блог |
Документация
БАЗА ДАННЫХ
Облако Datastore — удалось экспорта и импорта услуги: GA
объекты экспорта и импорта Облако Datastore с помощью облачной консоли, инструмент gcloud командной строки, или API Cloud Датастор. Используйте службу, чтобы оправиться от случайного удаления данных и экспорта данных для автономной обработки.
Документация
Облако Bigtable — новый регион: GA
Облако Bigtable теперь доступен в Франкфурте, Германия, (Европа-west3) регион — и каждый текущем регион GCP — дает вам доступ к Cloud Bigtable в регионе по вашему выбору.
Документация
Облако SQL — ключи шифрования клиент-управляемых (CMEK): GA
Зафиксируйте ваши конфиденциальные или регулируемые данные с CMEK, чтобы управлять своими собственными ключами шифрования данных в состоянии покоя. С поддержкой CMEK, Cloud SQL использует ключ клиента для доступа к данным.
Документация
Облако SQL — политика организации связи: GA
Централизованное управление настройками публичных IP для Cloud SQL, чтобы уменьшить поверхность атаки безопасности экземпляров Cloud SQL из Интернета. Ограничение доступа к экземплярам Cloud SQL: разрешить только частный доступ к IP или разрешить только Cloud SQL прокси доступ к IP-адрес.
Документация
Облако Bigtable — идентичность на уровне таблиц и управления доступом: GA
Используйте таблицу уровня IAM контролировать уровень каждого пользователя доступа к отдельным таблицам Cloud Bigtable.
Документация
Cloud Storage — Архив Класс хранения: GA
Хранить практически любой объем данных на нашей нижайшую стоимости услуги хранения с 11 девяток долговечности — и поддерживать доступ с миллисекундой латентностью. Используйте его для хранения холодных данных, аварийного восстановления, или для данных, которые вы планируете получить доступ менее чем один раз в год. Блог |
Документация
МИГРАЦИЯ
Migrate для Anthos: бета
Автоматическое преобразование и перенос экземпляров виртуальных машин — будь то на территории, на Google Cloud Platform, или на другие облака — к контейнерам в Kubernetes Engine. Перенесенные рабочие нагрузки полностью совместимы с GCP услуг, в том числе решений Stackdriver, Istio и Kubernetes в ГКП Marketplace.
страница продукта
Migrate для Anthos: GA
Миграция существующих VMware, Amazon EC2, Microsoft Azure, и Compute Engine виртуальных машин для контейнеров непосредственно на GKE в течение нескольких минут, свести к минимуму время простоя с потоковым миграции хранения, и автоматически преобразует рабочие нагрузки, как контейнеры в GKE стручков.
заметки о выпуске
Перенесите для V4.8 Compute Engine: GA
Миграция Microsoft Azure экземпляры в Compute Engine с повышенным масштабом, снижением первоначального простоем и способностью контролировать окружающую среду источника облака во время миграции. Дополнительные функции включают возможность управления обновлением системы и установку исправлений с помощью пользовательского интерфейса системы.
заметки о выпуске
AI & МАШИНА ОБУЧЕНИЯ
AI Платформа — пользовательские контейнеры: GA
Запускайте приложения в виде Докер изображения, создавая свой собственный контейнер для выполнения заданий на AI Platform. Использование машин рамок обучения и версий — а также не-ML зависимостей, библиотеки и двоичные файлы не иначе поддерживаются AI Platform.
Документация
AI Platform — использовать предопределенные имена машины типа для конфигурирования учебной работы: GA
Получите большую гибкость при распределении вычислительных ресурсов для машинного обучения рабочих мест, используя имена некоторых предопределенных типов машин Compute Engine. Вы также можете настроить свои графические процессоры использует работу, когда обучение с TensorFlow или используя пользовательские контейнеры.
Документация
Облако Video Intelligence API — обнаружение Логотип: бета
Обнаружить, отслеживать и распознавать присутствие более 100 000 марок и логотипов в видео-контенте.
Документация
Dialogflow — проверка агента: бета
Автоматически проверять ваш агент на наличие ошибок, когда вы тренируете его. Доступ к результатам из Dialogflow консоли или API, и игнорировать или исправлять ошибки, управлять качеством и производительностью вашего агента.
Документация
Dialogflow — регулярные выражения (регулярные выражения) для юридических лиц: GA
Теперь вы можете обеспечить регулярные выражения для создания агентов, структуры данных соответствуют друг другу — например, национальные идентификационные номера или номерных знаков — а не специфических терминов.
Документация
Dialogflow — нечеткое соответствие: GA
Тратьте меньше времени и усилий построения объектов — и упростить разработку. Объект согласование требует точного совпадения для одной из записей сущностей. Нечеткие соответствия позволяют компаниям идентифицировать матчи значения или синоним независимо от порядка слов.
Документация
AI Платформа Ноутбуки — поддержка CMEK для ноутбуков: бета
Использование ключей шифрования для клиента удалось зашифровать настойчивые диски на экземплярах ноутбуков.
Документация
Облако AutoML Vision — классификация изображений: бета-обновление
Единая инфраструктура теперь поддерживает как объект классификации и обнаружение, и имеет встроенный интерфейс. Планируйте заранее и подготовить модели классификации для общедоступности AutoML Видения планируется провести в этом году. Используйте следующие шаги для обновления существующих моделей. Примечания к выпуску |
Документация
Облако AutoML Vision — пакетный прогноз: бета
Использование пакетного прогнозирования для снижения затрат на умозаключения и более высокую пропускную способность, чем синхронный (онлайн) прогнозирования. Доступно как для классификации и обнаружения объектов.
заметки о выпуске
Облако AutoML Видение — TensorFlow.js интеграция: бета
Модели Экспорт AutoML Зрение Пограничные как TensorFlow.js пакетов. Модель край может быть развернут в различных платформах с поддержкой TensorFlow.js, включая все основные браузеры — и на стороне сервера в Node.js. Доступно как для классификации и обнаружения объектов.
заметки о выпуске
AutoML Таблица — ординатура данные для ЕС: бета
AutoML таблица теперь обеспечивает полную поддержку для пользователей с цензом оседлости данных ЕС.
Документация
Контактный центр AI: GA
Автоматизация взаимодействия центра обработки вызовов и обеспечение бесшовной передачи обслуживания для человека агентов с виртуальным агентом. Использование агент Assist транскрибировать вызовы в режиме реального времени, идентифицировать клиент намерения, а также обеспечить в режиме реального времени, шаг за шагом помощь ваших живых агентов.
Страница Решения
AutoML Natural Language — текст и классификация документов, анализ настроений, и экстракция организации: GA
Построение и развертывание пользовательских машинного обучения модели, анализирующие документы для того, чтобы классифицировать их, а также идентифицировать объекты и чувства в них. Блог |
Документация
Облако Зрение API — мульти-региональная поддержка оптического распознавания символов (OCR): GA
Доступ OCR функции и выбрать, где ваши данные будут обрабатываться в двух новых регионах: США и Европейского Союза.
Документация
AI Platform — встроенные классификации изображений и алгоритмы обнаружения объекта: бета
Поезд модели без написания кода с помощью встроенного в классификации изображений и обнаружения объектов алгоритмов. Используйте настройки гиперпараметра для большей точности, используйте TPUs для быстрой подготовки и экспорт моделей для прогнозирования, либо локально, либо развернуты AI Platform прогнозирования.
Документация
Virtual Private Cloud (VPC) — использование VPC Service управления с обучением AI Платформа: бета
Снизить риск эксфильтрации данных из ваших учебных заданий, выполнив их из проекта внутри службы по периметру с помощью элементов управления VPC Service, чтобы гарантировать, что Ваши данные не покидает периметр — в том числе обучающих данных ваших заходов рабочих мест и артефакты, которые он создает.
Документация
TensorFlow Enterprise — поддержка TensorFlow 2,1 на AI Платформа Deep Learning VM изображения: GA
Исследовать TensorFlow 2.1 функции, включая улучшение поддержки Cloud TPU, поддержку Intel MKL, смешанную точность подготовку для графических процессоров и TPU, и заплаток безопасности и исправления ошибок. Начало работы с TensorFlow предприятия на Deep Learning VM.
страница продукта
ЗДРАВООХРАНЕНИЕ И НАУКИ О ЖИЗНИ
Облако Науки о жизни API: бета
Процесс, анализировать и аннотировать геномика и биомедицинские данные в масштабе с использованием контейнерных рабочих процессов с Cloud Life Sciences. Ранее известный как Google Genomics, платформа теперь доступна в регионе Iowa (нам-central1), с другими регионами в ближайшее время.
Документация
Куратор решения теперь доступны в здравоохранении Marketplace: GA
Доступ к API Cloud Life Sciences и API Cloud Healthcare, а также широкий спектр решений, доступных на Google Cloud для медицинских и биологических наук, в здравоохранении Marketplace — и запустить их в облаке консоли с помощью всего лишь нескольких щелчков мыши.
Здоровье Marketplace
API ПЛАТФОРМЫ & ECOSYSTEMS
Apigee Край для частной облачной 4.19.06: GA
Исследуйте несколько юзабилити, производительности, безопасности и улучшения стабильности в последнем обновлении. Обширный список новых функций включает в себя вставную аналитику и поддержку развертывания HTTP и Cassandra стеллажи.
Страница продукта |
Документация
CLOUD COMMERCE
GCP Marketplace — поддержка виртуальных машин с несколькими сетевыми интерфейсными платами: GA
несколько сетевых интерфейсов Настройка с пользовательским интерфейсом, который интегрирует Compute Engine и GCP Marketplace и добавляет новые развертывания Менеджер Autogen особенности упростить и автоматизировать создание виртуальных машин с несколькими сетевыми картами.
Документация
БЕЗОПАСНОСТЬ
Облако Предотвращение потери данных — новый Google Cloud Platform Console пользовательский интерфейс: GA
Получите большую прозрачность и контроль над конфиденциальными данными с новым Cloud DLP UI. Проверьте и классифицировать данные в облачном хранилище, BigQuery и облачное DATASTORE хранилищ с несколькими щелчками мыши. Управление инспекции рабочих мест, создание шаблонов, а также изучить результаты в консоли.
Документация
Облако Asset Inventory — Организация политика и поддержка политика доступа: GA
Просмотр и оценка больше ресурсов и политических типов в одной централизованной, управляемой службы инвентаризации с вновь onboarded политики.
Документация
Идентичность Платформа поддержка мульти-аренда: бета
Создание уникальных элеваторов пользователей и конфигураций в рамках одного проекта Идентичность платформы для настройки границ данных изоляции. Бункеры могут представлять различные клиенты, бизнес-подразделения, дочерние компании или другие идентифицирующие признаки.
Документация
Менеджер ресурсов — новые ограничения организации политики: GA
Управление и безопасное обслуживание счетов в рамках вашей организации более эффективно с двумя новыми ограничениями политики, которые позволяют ограничить использование учетной записи службы: Создание Отключить Service Account и отключение учетной записи службы создания ключа.
Документация
Облако Управление идентификацией и доступом — описание учетной записи службы: GA
Добавить дополнительное описание для учетной записи службы для дальнейшей организации, выявления и дифференциации ваших счетов друг от друга.
Документация
Service Cloud Key Management — Cloud Внешний Key Manager: бета
Защитить данные в состоянии покоя в BigQuery и Compute Engine с использованием ключей шифрования, хранящихся и управляемых в системе управления ключами третьих сторон развернуты за пределами инфраструктуры Google. Блог |
Документация
Облако идентификация и управление доступом — Cloud IAM Условие: бета
Определение и соблюдение условного, атрибуты на основе контроля доступа к Google Cloud ресурсов. Установка времени на основе условий для запланированного, перерыв стекла, или временного доступа, а также условий на базе ресурсов для доступа с использованием сервиса, тип и имя ресурса соответствия приставки.
Документация
Секретный менеджер: бета
Надежно и удобно хранить и извлекать ключи API, жетоны, пароли, сертификаты и другие конфиденциальные данные.
Документация
FedRAMP добавляет Высокий и дополнительное Умеренное разрешение на Google Cloud Platform: GA
Запуск совместимых рабочих нагрузок на самом высоком уровне гражданской классификации с FedRAMP высокого разрешения для 17 продуктов Google Cloud в пяти облачных регионах. Кроме того, FedRAMP Умеренная авторизация расширилась до 64 продуктов в 17 облачных регионах.
Блог
Облако Asset Inventory — сервис уведомлений в режиме реального времени: GA
Создание подписки для непрерывных обновлений в режиме реального времени об изменениях ресурсов и политики для мониторинга диапазон поддерживаемых типов ресурсов — а также политики Облако управления идентификацией и доступом в организации, папки проекта или конкретного ресурса для Google Cloud Platform и Anthos.
Документация
Управление VPC Service — новые интеграции услуг: GA
Исследуйте весь спектр поддерживаемых продуктов и услуг, которые в настоящее время включают в себя облако ТПА, Облако Vision, и облако трассировку.
Документация
Читать дальше →